
今天我們來討論推薦系統,現在大家的生活環境充滿了推薦系統的應用,不管是在Youtube聽音樂或者是在商城購物,都充斥著推薦系統的應用。什麼是推薦系統?推薦系統就是一個用來預測使用者偏好的系統,並期盼透過推薦系統來增加企業營收或者增加其他效益。推薦系統演算法有非常多種,接下來會簡單說明:
隨機推薦:
大家可能覺得隨機推薦是什麼,其實就只是 random()。隨機投遞商品或物品給他。不要小看隨機推薦,在某些場景上,隨機的結果可能會比你運算非常久的結果還要好。雖然可恥,但有效
依照熱門排序:
透過熱度或者點閱率等等方式來直接推薦商品,對於某些時效性議題或商品非常有效!例如: 像最近很紅的氣炸鍋..等等。可能直接透過簡單的group by demographic,就可以得到一個不錯的初始效果。

Content-based filtering:
針對產品內容進行分析推薦,有時候像是針對Cold star問題 (全新商品,沒有使用者回饋),是有良好的效果。因為針對新的商品,你還是會有商品屬性等等的。你就可透過這些商品屬性分析去歸類及推薦。而像是以Content-based filtering很常看到的就是利用商品屬性matrix,利用相似度進行計算分析。最後的結果通常可解釋性的也較高 (Ex: 標籤)。或者是說在廣告的推薦上,可能就是利用一些廣告特徵直接預測點擊率 (Ex: logistic Regression or XGBoost 等)
Collaborative Filtering (協同過濾):
針對像是想要推薦 "買了什麼東西,還會買什麼東西" ,這樣的情境,而這樣的情境其中一中解決方案就是使用協同過濾。而協同過濾可分為兩類演算法 Model-based (Ex: LSTM)以及Memory-based ( Ex: User-based or item based)。
Model-based:
利用過去使用者歷史資料train出一個模型進行預測,像是利用LSTM來預測時間序列型的假設,當今天看完第一集,接下來可能會想看第二及第三集等等的。而Spotify就是曾經使用RNN做為音樂推薦的推薦系統之一
Memory-based:
基於使用者的相似度來推薦商品,他的假設就在於相似的人會喜歡相似的產品。像是User-based方法就是首先搜集使用者資訊,接下來利用相似度搜尋相似使用者(Ex: Cosine-similarity),最後產生推薦結果(Ex: Top-k)
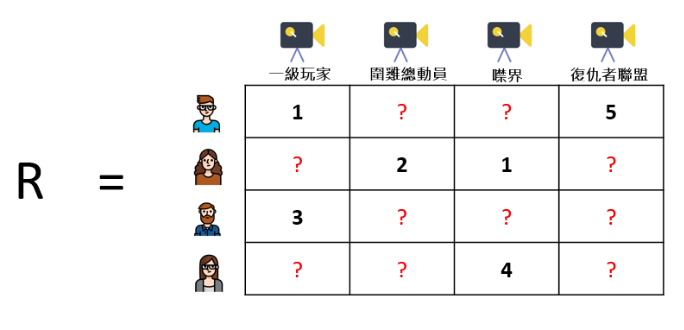
最來,來討論一下推薦系統最常遇到的問題
冷啟動(Cold Start):
推薦系統最常討論的就是Cold start問題,當今天有一個新的用戶或者新的商品的時候,我們該怎麼推薦的商品又或者這個商品該怎麼被推薦?因此,這是一個經典的推薦系統問題。而常見的解法有如前面所提到,可能會以新商品的屬性,或者新用戶的特徵等等的方式來做推薦。
探索問題(Exploit & Explore, EE):
Exploit,是指使用已知用戶偏好來做分析,Explore,則是指探索使用者未知的興趣或者偏好。如何透過一個好的推薦系統來做這些情境。可能例如一部分使用模型預測、一部分使用熱門、一部分使用隨機等等的方法。而如何取捨,都是商務面或者AB test等方式去執行。
今天是簡單的探討一下推薦系統,明天我們來嘗試實作 Google 過去所使用過的推薦系統 Deep & Wide。希望明天可以順利完成,最近常踩到 tf 2.0雷 ,尤其是 tf 1.x要轉換 tf 2.0的程式,雖然他有提供轉換程式,但還是會遇到許多問題,有機會都會在文章內分享。感謝今天漫長閱讀!

